
At last, it’s Friday! After a long week of hard work you deserve some time to relax and meet for a drink with friends. You make a few phone calls, everything is arranged and a few hours later you are out having a great time. And then the time comes to pay for the drinks. If you are lucky, there is a separate receipt for every drink If you are not lucky (and you usually aren’t), there is one receipt for all the drinks. Now you have to spend the next five minutes trying to decide who gets the receipt.
Why all the fuss about receipts, you may ask? If you live in Greece (and perhaps other places) in this time of economic woe, then this scenario is all too familiar. The Greek government, in its never-ending battle with tax evasion has come up with a plan! Every citizen must present an amount in receipts which depends on their income (using a tiered system). Any difference from the required amount (up to 15000 €) leads to either a penalty or credit equal to 10% of the difference. Note, that you can’t present receipts that are used in some other way to lower your taxable income (rent, utilities etc).
The main idea is to make citizens ask for receipts, so that businesses are forced to issue them. The secondary idea is to make citizens spend more. So much for savings…
In any case, near the end of the year, everyone in your group of close friends (the ones you go out with more often) ends up with a bunch of receipts. Some have enough receipts to cover their limit, some do not. Furthermore, some of the receipts are shared, in the sense that the one who has the receipt has paid for only some of the items on it. Being such good friends you decide that you should help each other out, so that, if possible, everyone reaches their limit and saves money.
Practical tax solidarity
There are several practical ways to help each other and they all share a common core. The receipts of each individual are first split into a private and public part. Each individual keeps their private part and the public part is split among the individuals that need it. By combining different ways to decide what receipts are public and private and how to split the public ones we can get several methods to help our friends. Some interesting methods are:
| private | public | split method | |
|---|---|---|---|
| 1 | nothing | all | equally among all |
| 2 | all until limit | the rest | among those that need it until limit, rest back to owners or equally among all |
| 3 | all until limit + 15000€ | the rest | among those that need it until limit, rest back to owners or equally among all |
| 4 | non-shared | shared | equally among all |
| 5 | non-shared + shared until limit | rest | equally among all |
If you are really good friends and the spirit of solidarity is high within the group, you may decide to try to split the receipts as evenly as possible within the group (method 1). This method maximizes the collective gain, but hurts the individuals that have originally a larger amount in receipts. This may not be a problem, though, and may actually be the most fair way to handle the situation if the number of shared receipts in the group is high.
Another way (method 2) is for every person to keep enough of their receipts so that they reach the limit (if they can, of course) and add the rest to the group’s surplus collection. The receipts from the surplus collection are then distributed to those that don’t have enough receipts to reach the limit on their own. Any remaining receipts are then either returned to their original owners or equally split within the group.
A variation of the previous method is method 3. In this case we use limit + 15000€ for the private receipts, so that individuals get the maximum benefit from their receipts. Unfortunately, this method rarely leaves any receipts for the surplus and is quite unfair if there is a large number of shared receipts.
Methods 4 and 5 assume that each receipt can be easily identified as shared or non-shared. In method 4 individuals keep only the receipts that are non-shared and add the shared receipts to the surplus. In method 5 individuals first use their non-shared receipts and then start using the shared ones until they reach the limit. If the receipts were originally distributed randomly, then method 4 is the fairest way to handle things. On the other hand, if shared receipts were originally given to the person with the highest expense then perhaps method 5 is a bit more fair.
Handling NP-completeness
Whatever way you choose to help your friends, the same basic problem must be solved: how can you evenly partition a set of receipts among a number of individuals?
This problem, as innocent as it may look, is actually NP-complete! Its official name is the “partition problem” and in its optimization version is stated as:
Partition a multiset of integers S into n subsets 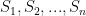
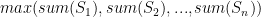
In plain words, split a multiset of integers into n subsets as evenly (as far as the sum of each subset is concerned) as possible. The classic version involves only two subsets. The difficulty lies in the fact that we are not allowed to split each integer (receipt amount in our case) arbitrarily.
Being NP-complete practically means that in the worst case we have to go through all the partitioning combinations to find the best. The combinations being persons^receipts, this is *not* what I call a fun past-time.
So, is this all part of an evil plot by the tax service to get our hard-earned income? Even if it is, we are not completely helpless! The partition problem is often called the “Easiest Hard Problem”. The reason is that under some conditions, which have been extensively studied, there are heuristic methods that provide very good results.
These conditions state that if we take 
![[1, 2^m]](https://s0.wp.com/latex.php?latex=%5B1%2C+2%5Em%5D&bg=ffffff&fg=000000&s=0&c=20201002)
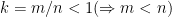
![[a, b]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![[1, b - a +1]](https://s0.wp.com/latex.php?latex=%5B1%2C+b+-+a+%2B1%5D&bg=ffffff&fg=000000&s=0&c=20201002)

Intuitively, the above condition makes perfect sense: it is much more probable to be able to split a multiset into subsets with equal sums if that multiset has many small values (where small is relative to the cardinality of the set). As the values get larger and/or the set size becomes smaller it is much less probable to be able to find a perfect split.
So, how does our problem instance fare with regard to this criterion? First of all, we have to make a minor adjustment because the condition refers to integers but cash amounts are real numbers with two decimal digits. This can be easily countered by expressing all amounts as euro-cents. The amount on each receipt is hardly ever outside the [1, 6553600] range (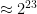

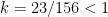
Now that we know that there is a good chance of being able to solve the problem, how do we actually go about it? The algorithm is surprisingly straightforward. Of course, it does not strictly solve the problem, but it produces an approximate solution that is good enough for our purposes. The algorithm is:
1. Sort the numbers in descending order [ O(nlogn) on average ]
2. Process each number (in sorted order): [ Θ(n) ]
2.1 Find the subset with the least sum [ O(logp) using priority queues ]
2.2 Add the number to the subset [ Θ(1) ]
where n: number of receipts
p: number of persons
This gives us T(n, p) = O(nlogn + nlogp + n). For a constant number of persons this leads to T(n) = O(nlogn). Not bad for “solving” an NP-complete problem! This algorithm has been proved to produce results relatively close to the optimal solution. Its discrepancy (the difference in value of the sums of the produced subsets) is O(1/n). There are other algorithms that can do a bit better, but they are considerably more complicated (and not worth it for our puny purpose).
Finally, because “an ounce of action is worth a ton of theory”, I have developed a proof of concept application that implements some of the methods mentioned above. You can find it at https://code.launchpad.net/~afrantzis/+junk/tax-solidarity-trunk. It is written in python and licensed under the AGPL 3.0+.
Take that, tax service! YOUR NEFARIOUS SCHEME WILL NEVER SUCCEED!
References
- Karmarker, Narenda and Karp, Richard M., The Differencing Method of Set Partitioning, Techreport, UC Berkley, 1983
- Brian Hayes, The Easiest Hard Problem, American Scientist, March-April 2002
- Stephan Mertens, The Easiest Hard Problem: Number Partitioning, Computational Complexity and Statistical Physics, 2006
